Масштабирование
Описание
Эта примерная архитектура предназначена для обеспечения масштабируемости. Она включает три узла: два объединенных сервера ClickHouse плюс координацию (ClickHouse Keeper) и третий сервер с только ClickHouse Keeper для завершения кворума из трех. С помощью этого примера мы создадим базу данных, таблицу и распределенную таблицу, которая сможет запрашивать данные на обоих узлах.
Уровень: Базовый
Terminology
Replica
A copy of data. ClickHouse always has at least one copy of your data, and so the minimum number of replicas is one. This is an important detail, you may not be used to counting the original copy of your data as a replica, but that is the term used in ClickHouse code and documentation. Adding a second replica of your data provides fault tolerance.
Shard
A subset of data. ClickHouse always has at least one shard for your data, so if you do not split the data across multiple servers, your data will be stored in one shard. Sharding data across multiple servers can be used to divide the load if you exceed the capacity of a single server. The destination server is determined by the sharding key, and is defined when you create the distributed table. The sharding key can be random or as an output of a hash function. The deployment examples involving sharding will use rand() as the sharding key, and will provide further information on when and how to choose a different sharding key.
Distributed coordination
ClickHouse Keeper provides the coordination system for data replication and distributed DDL queries execution. ClickHouse Keeper is compatible with Apache ZooKeeper.
Окружение
Диаграмма архитектуры
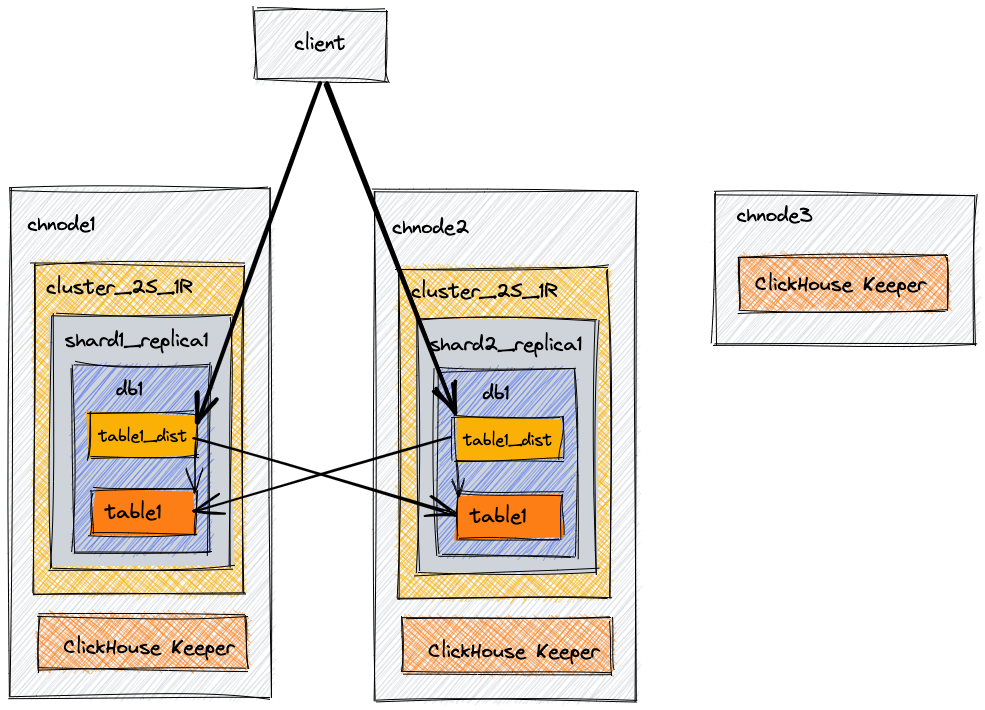
| Узел | Описание |
|---|---|
chnode1 | Данные + ClickHouse Keeper |
chnode2 | Данные + ClickHouse Keeper |
chnode3 | Используется для кворума ClickHouse Keeper |
В продуктивных средах мы настоятельно рекомендуем, чтобы ClickHouse Keeper работал на выделенных хостах. Эта базовая конфигурация запускает функциональность Keeper внутри процесса сервера ClickHouse. Инструкции для развертывания ClickHouse Keeper в отдельности доступны в документации по установке.
Установка
Установите ClickHouse на три сервера, следуя инструкциям для вашего типа архива (.deb, .rpm, .tar.gz и т.д.). Для этого примера вам необходимо следовать инструкциям по установке сервера и клиента ClickHouse на всех трех машинах.
Редактирование файлов конфигурации
When configuring ClickHouse Server by adding or editing configuration files you should:
- Add files to
/etc/clickhouse-server/config.d/directory - Add files to
/etc/clickhouse-server/users.d/directory - Leave the
/etc/clickhouse-server/config.xmlfile as it is - Leave the
/etc/clickhouse-server/users.xmlfile as it is
Конфигурация chnode1
Для chnode1 имеется пять файлов конфигурации. Вы можете объединить эти файлы в один, но для ясности в документации может быть проще рассмотреть их отдельно. При чтении файлов конфигурации вы увидите, что большая часть конфигурации одинакова между chnode1 и chnode2; отличия будут выделены.
Конфигурация сети и логирования
Эти значения могут быть настроены по вашему усмотрению. Эта примерная конфигурация предоставляет вам журналы отладки, которые будут автоматически перезаписываться при достижении 1000M три раза. ClickHouse будет слушать на сети IPv4 на портах 8123 и 9000, и будет использовать порт 9009 для межсерверной связи.
Конфигурация ClickHouse Keeper
ClickHouse Keeper предоставляет координационную систему для репликации данных и выполнения распределенных DDL-запросов. ClickHouse Keeper совместим с Apache ZooKeeper. Эта конфигурация включает ClickHouse Keeper на порту 9181. Выделенная строка указывает, что этот экземпляр Keeper имеет server_id равный 1. Это единственное отличие в файле enable-keeper.xml между тремя серверами. chnode2 будет иметь server_id, установленный на 2, а chnode3 будет иметь server_id, установленный на 3. Раздел конфигурации raft одинаков на всех трех серверах и выделен ниже, чтобы показать вам взаимосвязь между server_id и экземпляром server в конфигурации raft.
Если по какой-либо причине узел Keeper заменяется или восстанавливается, не используйте существующий server_id. Например, если узел Keeper с server_id равным 2 восстанавливается, дайте ему server_id равный 4 или выше.
Конфигурация макросов
Макросы shard и replica уменьшают сложность распределенного DDL. Заданные значения автоматически заменяются в ваших DDL-запросах, что упрощает ваш DDL. Макросы для этой конфигурации указывают номер шарда и реплики для каждого узла. В этом примере с 2 шардом и 1 репликой макрос реплики равен replica_1 как на chnode1, так и на chnode2, так как имеется только одна реплика. Макрос шарда равен 1 на chnode1 и 2 на chnode2.
Конфигурация репликации и шардирования
Начнем сверху:
- Раздел
remote_serversв XML указывает каждый из кластеров в окружении. Атрибутreplace=trueзаменяет примерremote_serversв стандартной конфигурации ClickHouse на конфигурациюremote_servers, указанную в этом файле. Без этого атрибута удаленные серверы в этом файле были бы добавлены в список примеров в стандартной конфигурации. - В этом примере имеется один кластер с именем
cluster_2S_1R. - Создается секрет для кластера с именем
cluster_2S_1Rсо значениемmysecretphrase. Секрет общается между всеми удаленными серверами в окружении, чтобы обеспечить их корректное объединение. - Кластер
cluster_2S_1Rимеет два шарда, и каждый из этих шардов имеет одну реплику. Посмотрите на диаграмму архитектуры в начале этого документа и сравните ее с двумя определениямиshardв XML ниже. В каждом из определений шардов имеется одна реплика. Реплика предназначена для этого конкретного шарда. Хост и порт для этой реплики указаны. Реплика для первого шарда в конфигурации хранится наchnode1, а реплика для второго шарда в конфигурации хранится наchnode2. - Внутренняя репликация для шардов установлена в true. Каждый шард может иметь параметр
internal_replication, определенный в файле конфигурации. Если этот параметр установлен в true, операция записи выбирает первую здоровую реплику и записывает данные в нее.
Настройка использования Keeper
Выше было настроено несколько файлов ClickHouse Keeper. Этот файл конфигурации use-keeper.xml настраивает ClickHouse Server для использования ClickHouse Keeper для координации репликации и распределенных DDL. Этот файл указывает, что ClickHouse Server должен использовать Keeper на узлах chnode1 - 3 на порту 9181, и файл одинаков на chnode1 и chnode2.
Конфигурация chnode2
Поскольку конфигурация на chnode1 и chnode2 очень похожа, здесь будут указаны только отличия.
Конфигурация сети и логирования
Конфигурация ClickHouse Keeper
Этот файл содержит одно из двух различий между chnode1 и chnode2. В конфигурации Keeper server_id установлен на 2.
Конфигурация макросов
Конфигурация макросов имеет одно из различий между chnode1 и chnode2. shard установлен на 2 на этом узле.
Конфигурация репликации и шардирования
Настройка использования Keeper
Конфигурация chnode3
Поскольку chnode3 не хранит данные и используется только для ClickHouse Keeper для обеспечения третьего узла в кворуме, chnode3 имеет только два файла конфигурации: один для настройки сети и логирования и один для настройки ClickHouse Keeper.
Конфигурация сети и логирования
Конфигурация ClickHouse Keeper
Тестирование
- Подключитесь к
chnode1и подтвердите, что кластерcluster_2S_1R, сконфигурированный выше, существует
- Создайте базу данных в кластере
- Создайте таблицу с движком MergeTree в кластере.
Мы не должны указывать параметры на движке таблицы, так как они будут автоматически определены на основе наших макросов
- Подключитесь к
chnode1и вставьте строку
- Подключитесь к
chnode2и вставьте строку
- Подключитесь к любому узлу,
chnode1илиchnode2, и вы увидите только ту строку, которая была вставлена в эту таблицу на этом узле. например, наchnode2
- Создайте распределенную таблицу, чтобы запрашивать оба шарда на обоих узлах.
(В этом примере функция
rand()установлена в качестве ключа шардирования, чтобы случайным образом распределять каждую вставку)
- Подключитесь к любому из узлов
chnode1илиchnode2и запросите распределенную таблицу, чтобы увидеть обе строки.