Миграция данных из Redshift в ClickHouse
Связанный контент
Введение
Amazon Redshift — популярное облачное решение для хранения данных, которое является частью предложений Amazon Web Services. Этот гид представляет различные подходы к миграции данных из экземпляра Redshift в ClickHouse. Мы рассмотрим три варианта:
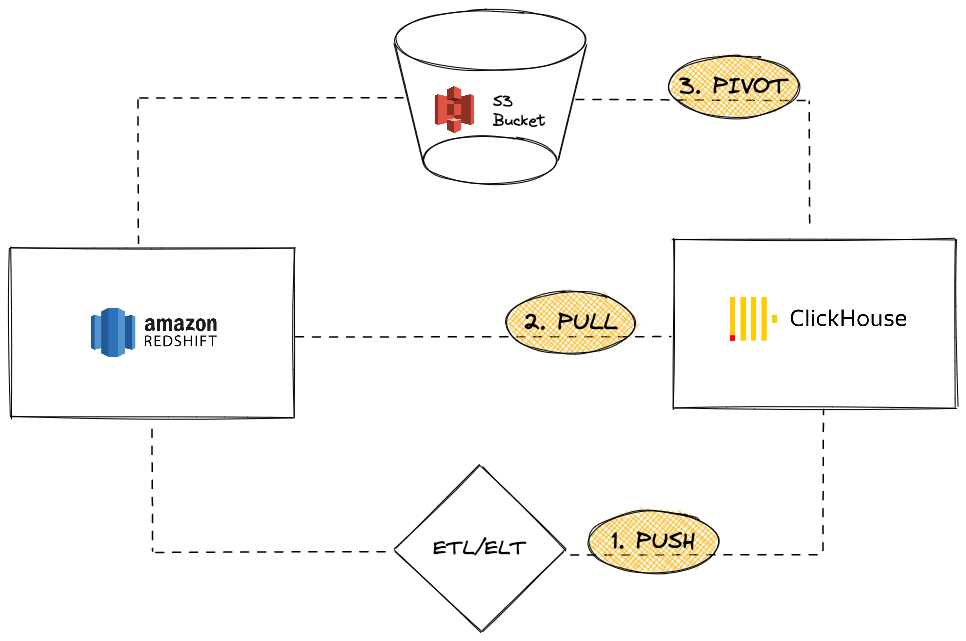
С точки зрения экземпляра ClickHouse, вы можете:
-
PUSH данные в ClickHouse, используя сторонний инструмент или сервис ETL/ELT
-
PULL данные из Redshift с использованием ClickHouse JDBC Bridge
-
PIVOT с использованием объектного хранилища S3, применяя логику «Выгрузить, затем загрузить»
В этом учебнике мы использовали Redshift в качестве источника данных. Тем не менее, представленные подходы миграции не являются эксклюзивными для Redshift, и аналогичные шаги могут быть применены к любому совместимому источнику данных.
Передача данных из Redshift в ClickHouse
В сценарии передачи данные отправляются с помощью стороннего инструмента или сервиса (либо кастомного кода, либо ETL/ELT), чтобы отправить ваши данные в экземпляр ClickHouse. Например, вы можете использовать программное обеспечение, такое как Airbyte, чтобы перемещать данные между вашим экземпляром Redshift (в качестве источника) и ClickHouse в качестве назначения (см. наш гид по интеграции для Airbyte)

Плюсы
- Использует существующий каталог коннекторов ETL/ELT программного обеспечения.
- Встроенные возможности для синхронизации данных (добавление/перезапись/инкрементная логика).
- Позволяет сценарии преобразования данных (например, см. наш гид по интеграции для dbt).
Минусы
- Пользователям необходимо настраивать и поддерживать инфраструктуру ETL/ELT.
- Внесение стороннего элемента в архитектуру, что может стать потенциальным узким местом в масштабируемости.
Извлечение данных из Redshift в ClickHouse
В сценарии извлечения идея заключается в использовании ClickHouse JDBC Bridge для непосредственного подключения к кластеру Redshift из экземпляра ClickHouse и выполнения запросов INSERT INTO ... SELECT:

Плюсы
- Обобщенный для всех инструментов, совместимых с JDBC
- Элегантное решение для выполнения запросов к нескольким внешним источникам данных из ClickHouse
Минусы
- Требуется экземпляр ClickHouse JDBC Bridge, что может стать потенциальным узким местом в масштабируемости
Хотя Redshift основан на PostgreSQL, использование функции таблицы или движка таблицы ClickHouse для PostgreSQL невозможно, так как ClickHouse требует версию PostgreSQL 9 или выше, а API Redshift основан на более ранней версии (8.x).
Учебник
Чтобы использовать этот вариант, необходимо настроить ClickHouse JDBC Bridge. ClickHouse JDBC Bridge — это автономное Java-приложение, которое обрабатывает соединение JDBC и служит прокси между экземпляром ClickHouse и источниками данных. Для этого учебника мы использовали предварительно заполненный экземпляр Redshift с образцом базы данных.
- Разверните ClickHouse JDBC Bridge. Для получения дополнительной информации смотрите наш пользовательский гид по JDBC для внешних источников данных
Если вы используете ClickHouse Cloud, вам нужно будет запустить ClickHouse JDBC Bridge в отдельной среде и подключиться к ClickHouse Cloud с помощью функции remoteSecure
- Настройте источник данных Redshift для ClickHouse JDBC Bridge. Например,
/etc/clickhouse-jdbc-bridge/config/datasources/redshift.json
- Как только ClickHouse JDBC Bridge будет развернут и запущен, вы можете начать выполнять запросы к вашему экземпляру Redshift из ClickHouse
- Далее мы покажем импорт данных с помощью оператора
INSERT INTO ... SELECT
Пивот данных из Redshift в ClickHouse с использованием S3
В этом сценарии мы экспортируем данные в S3 в промежуточном формате пивота, а затем загружаем данные из S3 в ClickHouse.
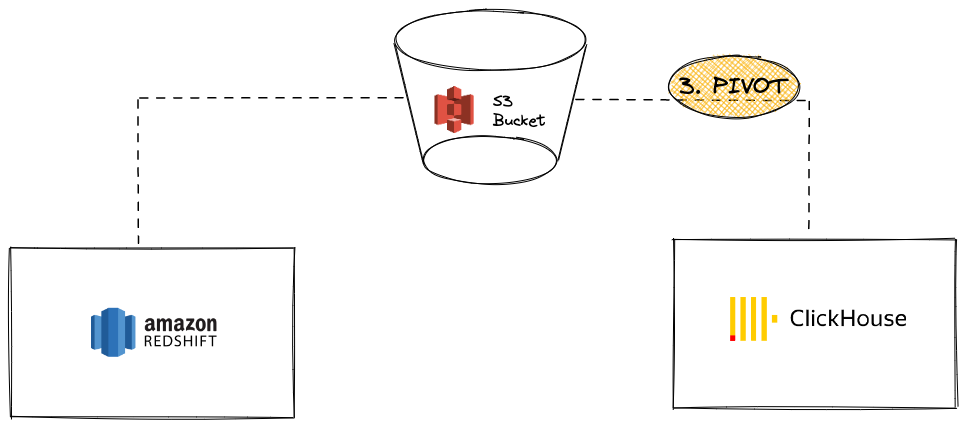
Плюсы
- И Redshift, и ClickHouse обладают мощными функциями интеграции с S3.
- Использует существующие функции, такие как команда
UNLOADв Redshift и функция таблицы / движок таблицы S3 в ClickHouse. - Масштабируется без проблем благодаря параллельному чтению и высокой пропускной способности между S3 и ClickHouse.
- Может использовать сложные и сжатые форматы, такие как Apache Parquet.
Минусы
- Два шага в процессе (выгрузка из Redshift, затем загрузка в ClickHouse).
Учебник
-
Используя функцию UNLOAD в Redshift, экспортируйте данные в существующее частное S3 хранилище:
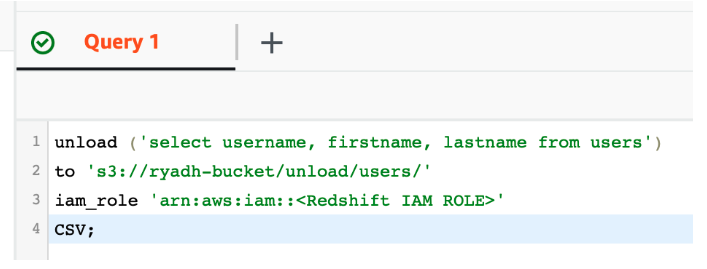
Это приведет к созданию файлов частей, содержащих необработанные данные в S3

-
Создайте таблицу в ClickHouse:
В качестве альтернативы ClickHouse может попробовать вывести структуру таблицы, используя
CREATE TABLE ... EMPTY AS SELECT:Это особенно хорошо работает, когда данные находятся в формате, содержащем информацию о типах данных, как Parquet.
-
Загрузите S3 файлы в ClickHouse с помощью оператора
INSERT INTO ... SELECT:
В этом примере использовался CSV в качестве формата пивота. Тем не менее, для производственных задач мы рекомендуем использовать Apache Parquet в качестве лучшего варианта для крупных миграций, так как он содержит сжатие и может сэкономить некоторые затраты на хранение, одновременно уменьшая время передачи. (По умолчанию каждая группа строк сжимается с использованием SNAPPY). ClickHouse также использует колонкоориентированность Parquet для ускорения приема данных.